
When Dual-Tasking Works, When It Doesn't, and Why
The Core Architecture: Your Brain Has a Bottleneck
The foundational finding in multitasking research, replicated hundreds of times since Pashler's landmark 1994 review, is that the brain's response selection mechanism operates serially. When two tasks both need the central processor to make a decision, one waits for the other. This is the Psychological Refractory Period (PRP) effect: present two stimuli in rapid succession, and the response to the second one is reliably delayed by however long the first one is still occupying the central stage (Pashler, 1994; Sigman & Dehaene, 2006).
This isn't a minor lab curiosity. The PRP effect is described as "highly robust" across decades of research and is observed regardless of whether the two tasks use the same hands, different hands, voice responses, foot responses, or eye movements (Pashler, 1994). It persists even when the tasks seem completely unrelated.
But the bottleneck story is more nuanced than "you can't do two things at once." It depends critically on what kind of cognitive resources the tasks require.
Wickens Multiple Resource Theory: The Key Framework
Christopher Wickens' 4-Dimensional Multiple Resource Model (1980, 2002, 2008) explains why some task pairs interfere catastrophically while others coexist relatively well. The model identifies four dimensions along which cognitive resources are differentiated:
- Processing stages: Perceptual/cognitive vs. response
- Sensory modalities: Visual vs. auditory
- Processing codes: Spatial vs. verbal
- Visual channels: Focal vs. ambient
The prediction is straightforward: two tasks that draw on different resource pools along these dimensions interfere less than two tasks that draw on the same pools. Listening to a podcast (auditory/verbal) while driving (visual/spatial/motor) works reasonably well because the tasks draw on largely separate resource pools. Reading a text while listening to someone speak (both verbal) is much harder because they compete for the same verbal processing resource.
Wickens' computational model yields high correlations between predicted and observed interference across dozens of task combinations (Wickens, 2008). This is the best empirical framework we have for predicting when dual-tasking will or won't cost you.
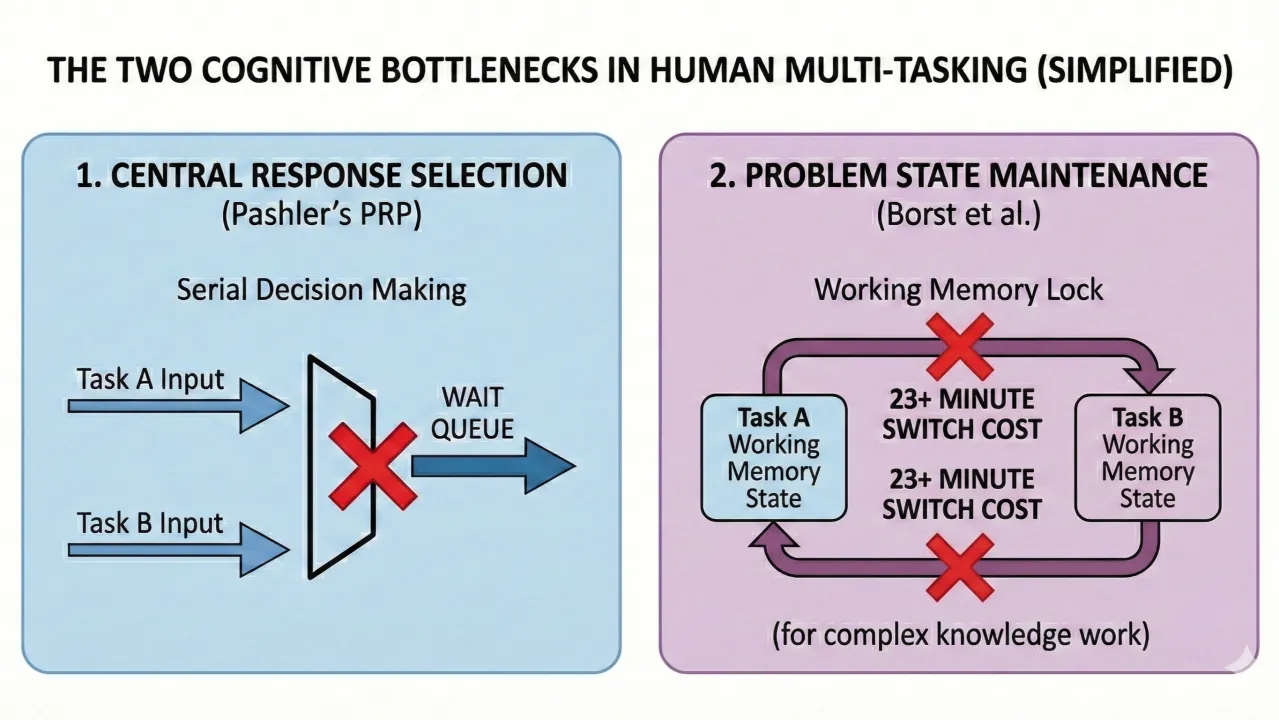
The Problem State Bottleneck: Why Knowledge Work Is Different
Beyond the general central bottleneck and Wickens' resource pools, there's a more specific bottleneck that is especially relevant to knowledge work: the problem state bottleneck, identified by Borst, Taatgen, and van Rijn (2010).
The "problem state" is the intermediate mental representation you hold while working through a task — the current step of a multi-step calculation, the logical structure of an argument you're building, the architectural pattern you're implementing in code, the thread of reasoning in a document you're editing.
Borst et al. demonstrated experimentally that people can maintain only one active problem state at a time. When two tasks both require maintaining a problem state, interference is severe and "overadditive" — worse than the sum of each task's individual demands. When only one task requires a problem state (and the other is more automatic), interference is minimal.
This finding was confirmed across three experiments and validated with computational models in the ACT-R cognitive architecture. Subsequent work (Held, Rieger, & Borst, 2024) showed that working memory contention, not a general central coordinator, best explains the interference pattern in dual-task settings.
This is the critical insight for anyone doing coding, writing, planning, or analytical work. These tasks all require maintaining a complex problem state. Writing a spec requires holding the logical structure of the document. Coding requires holding the state of the implementation. Debugging requires holding a mental model of data flow. They all contend for the same limited problem-state resource.
Salvucci & Taatgens Threaded Cognition: When Interleaving Can Work
The most sophisticated model of multitasking is Salvucci and Taatgen's Threaded Cognition theory (2008), which treats concurrent tasks as independent "threads" that are coordinated by a serial procedural resource and executed across other available resources (visual, auditory, motor, memory).
The key mechanism: when one thread is waiting for a slow resource (e.g., a motor response, a memory retrieval, an external event), other threads can use the procedural resource in the gap. Tasks interleave through the idle slots in each other's processing, not through parallel execution.
This means dual-tasking can approach zero cost under specific conditions:
- One or both tasks have substantial idle/waiting periods where the procedural resource isn't needed
- The tasks use different peripheral resources (e.g., one visual, one auditory; one manual, one vocal)
- Neither task's problem state is disrupted by the other task's processing
When these conditions hold, threading is efficient. When they don't — particularly when both tasks compete for the problem state resource — interference is substantial and unavoidable.
Can Training Improve Dual-Task Performance?
A natural question follows from the bottleneck research: if the bottleneck limits dual-tasking, can practice reduce or eliminate that limit? The answer is nuanced — training can dramatically improve dual-task performance, but the mechanisms and boundary conditions matter enormously for anyone hoping to apply this to real work.
Three Competing Hypotheses
Ruthruff, Van Selst, Johnston, and Remington (2006) tested three hypotheses about how practice reduces dual-task interference:
- Task integration: Practice teaches you to efficiently coordinate a specific task pair as a unit
- Automatization: Practice makes individual tasks automatic, allowing them to bypass the central bottleneck entirely
- Stage shortening: Practice speeds up the bottleneck stages (response selection gets faster), but the bottleneck itself remains intact
Their transfer-of-training experiments found that for most participants, the third hypothesis — stage shortening with an intact bottleneck — fully explained the improvement. The bottleneck didn't disappear; tasks just moved through it faster. However, a minority of participants in certain conditions did show evidence of genuine automatization, bypassing the bottleneck altogether.
The Neural Evidence: Faster Processing, Not Parallel Processing
Dux, Tombu, Harrison, Rogers, Tong, and Marois (2009) provided the clearest neural account. They trained participants daily for two weeks on two simple sensorimotor tasks while tracking brain activity with fMRI. Key findings:
- Training reduced dual-task costs by approximately 50% over two weeks
- The improvement was driven by faster, more efficient information processing in the posterior lateral prefrontal cortex (the neural locus of the bottleneck)
- Training did not create parallel processing pathways — the brain was still processing one task at a time
- As Dux stated: "Even after extensive practice, our brain does not really do two tasks at once. It is still processing one task at a time, but it does it so fast it gives us the illusion we are doing two tasks simultaneously."
The prefrontal cortex showed decreased and more efficient activation patterns with training, and pattern analysis revealed that neural representations of the two tasks became more distinct — the brain was sharpening its task representations rather than learning to run them simultaneously.
Verghese, Garner, Mattingley, and Dux (2016) followed up with a 100-person study showing that the volume of the left dorsolateral prefrontal cortex predicted individual training gains — meaning some people are structurally better positioned to benefit from dual-task training than others.
Bottleneck Bypass: Possible but Extremely Narrow
While stage shortening is the dominant mechanism, genuine bottleneck bypass — where a practiced task runs in parallel with an unpracticed one — has been demonstrated under very specific conditions.
Schumacher, Seymour, Glass, Fencsik, Lauber, Kieras, and Meyer (2001) showed that after relatively modest practice (five sessions), some participants achieved "virtually perfect time sharing" on basic choice reaction tasks. Maquestiaux, Lague-Beauvais, Ruthruff, and Bherer (2008) found that after six sessions of single-task practice on a simple auditory-vocal task, 17 out of 20 young adults could bypass the bottleneck when that task was paired with an unpracticed visual-manual task.
But the conditions required for bypass are revealing:
- The tasks must be simple sensorimotor mappings with consistent stimulus-response associations (e.g., press left for low tone, press right for high tone)
- Sensory-motor modality compatibility matters enormously: bypass works best with compatible pairings (visual-manual + auditory-vocal) and fails with incompatible ones (visual-vocal) because incompatible pairings create conflicts within modality-specific working memory (Maquestiaux, Ruthruff, Defer, and Ibrahime, 2018)
- The practiced task must not greedily recruit central resources: even tasks that can run automatically will seize the bottleneck when it's available, re-creating interference (Maquestiaux et al., 2008)
- It requires thousands of training trials on consistent mappings — the kind of repetitive practice that has no analog in knowledge work
Age Sharply Limits Bypass Capacity
Maquestiaux, Lague-Beauvais, Ruthruff, Hartley, and Bherer (2010) found a dramatic age difference: while the vast majority of young adults bypassed the bottleneck after training, at most 1 out of 12 older adults could do so — even with identical training. Maquestiaux, Didierjean, Ruthruff, Chauvel, and Hartley (2013) replicated this with double the training (10,080 trials across 12 sessions). Older adults' single-task reaction times dropped to levels identical to young adults, yet they still could not bypass the bottleneck. The ability to automatize novel tasks to the point of bottleneck bypass appears to decline with age, independent of overall processing speed.
The Coordination Skills Hypothesis
Strobach and Schubert (2024) reviewed evidence for a "memory hypothesis" of dual-task improvement: practice doesn't eliminate the bottleneck or make tasks automatic, but instead improves the executive ability to rapidly load both task sets into working memory at the start of a dual-task trial. This coordination skill — efficiently instantiating and switching between task representations — explains why dual-task practice sometimes transfers to new task combinations that share similar coordination demands.
However, the authors explicitly note that this hypothesis has only been investigated with relatively easy component tasks. Whether it generalizes to complex tasks with high working memory demands remains unknown.
Transfer Is Severely Limited
Perhaps the most practically important finding: dual-task training benefits are overwhelmingly task-specific.
Bender, Filmer, Garner, Dux, and colleagues (2017) trained participants on a combined visuomotor tracking and discrimination task for six sessions. Multitasking performance on the trained tasks improved substantially, but this improvement "did not generalize to a wide range of cognitive tasks that are theoretically linked to the current dual-task paradigm." The conclusion: training induces learning of task-specific coordination skills, not a general enhancement of multitasking ability.
Ewolds, Broeker, de Oliveira, Raab, and Kunzell (2021) found that even when two tasks were made individually predictable through practice, the benefits of predictability remained contained within each task — they didn't combine to reduce overall dual-task interference. Dual-task practice didn't change this.
Meta-analyses of cognitive training more broadly (Sala & Gobet, 2017; Kassai, Futo, Demetrovics, & Takacs, 2019) consistently find that training produces "near transfer" (improvement on similar tasks) but not "far transfer" (improvement on dissimilar cognitive abilities). As one review summarized: training a component did not have a significant effect on untrained components.
One Notable Exception: NeuroRacer
Anguera, Boccanfuso, Rintoul, and Gazzaley (2013), published in Nature, demonstrated something unusual. Older adults (60-85) who trained on NeuroRacer — a custom 3D video game requiring simultaneous driving and sign detection — not only improved their multitasking performance beyond untrained 20-year-olds, but showed transfer to untrained cognitive abilities including sustained attention and working memory. These gains persisted for six months. Neural measures showed enhanced prefrontal theta power resembling patterns seen in younger brains.
The critical nuance: the researchers argued this transfer occurred because NeuroRacer enhanced general cognitive control processes (the ability to maintain an engaged, goal-directed state under interference), not multitasking ability per se. The game's adaptive difficulty algorithm continuously pushed participants beyond their comfort zone, preventing the automatic processing that typically limits training effects. This is more about training the executive control system than about making dual-tasking easier.
What This Means for Knowledge Work
The training research carries a clear, somewhat uncomfortable implication for knowledge workers:
What training *can* do: Speed up processing of well-practiced, routine task components. If you process the same types of Slack messages, the same types of code review comments, or the same types of form-filling operations hundreds of times, the response selection for those tasks will get faster, leaving more room for interleaving with other work.
What training *cannot* do: Make novel, complex cognitive tasks run in parallel. You cannot "practice" your way into simultaneously writing a design doc and debugging a production issue. These tasks inherently require the problem state resource, involve novel combinations of information, and demand the kind of central executive engagement that resists automatization. The bottleneck isn't a skill deficit — it's a structural feature of how cognition works.
What training *might* do: Improve your general cognitive control — your ability to maintain focus, resist distraction, and manage interference. But this is best achieved through sustained, adaptive cognitive challenge, not through practicing multitasking itself.
What Happens Beyond Two Tasks
Research on triple-tasking is limited but the results that exist are stark.
Stefani, Sauter, and Mack (2025) directly tested the transition from dual-task to triple-task performance. Key findings:
- Response times increased from single to dual to triple tasks, but the increase from dual to triple was only about 43% of the increase from single to dual, suggesting a non-linear (but still costly) scaling pattern
- Unlike in dual tasks where typically only one of the two responses is delayed, in triple tasks all three subtasks showed elevated response times
- Even with extensive dual-task training beforehand, triple-task costs persisted — preparation helped initially but the advantage diminished over sessions
- Task coordination, rather than simple stimulus-response mapping, became the dominant source of interference
Konishi, Berberian, de Gardelle, and Sackur (2021) found something arguably more alarming: triple-tasking didn't just degrade performance on the three tasks — it degraded participants' awareness of how well they were performing (metacognitive sensitivity). People became worse at the tasks and worse at knowing they were worse. This metacognitive impairment was independent of the performance cost itself, suggesting it reflects an additional resource demand that monitoring and self-evaluation place on the same limited cognitive machinery.
This means that the subjective feeling of "managing well" during heavy multitasking is itself unreliable evidence.
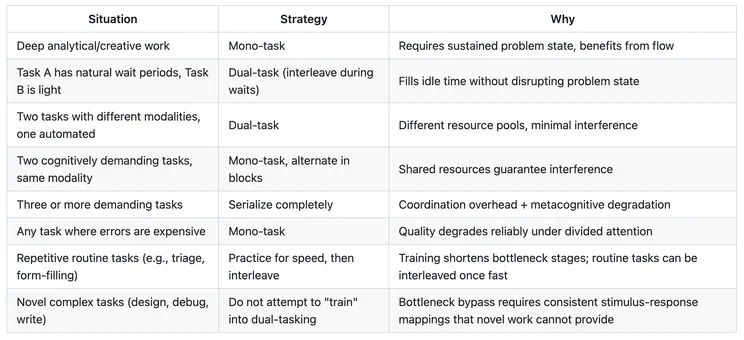
The Conditions Where Dual-Tasking Actually Works
Synthesizing across the bottleneck research, multiple resource theory, threaded cognition, and the problem state findings, dual-tasking provides net benefit over mono-tasking specifically when:
1. One task has genuine idle time that the other can fill.
This is the throughput argument. If Task A involves 40% active cognition and 60% waiting (for a build, a query, a response from someone), and Task B can productively fill those wait periods without disrupting Task A's problem state when Task A becomes active again, total throughput increases. This is not multitasking in the popular sense — it's efficient scheduling of a serial processor.
Examples: monitoring CI output while drafting notes; reviewing a slow-loading dashboard while composing a message; waiting for a deploy while scanning a queue of simple approvals.
2. The tasks draw on different resource pools (per Wickens).
Listening to ambient music (auditory, no verbal processing demand) while coding (visual, verbal, spatial). Walking while having a phone conversation. These work because the tasks don't compete for the same perceptual, cognitive, or motor resources.
What doesn't work: reading Slack while writing a document (both visual, both verbal, both require a problem state). Reviewing code while participating in a meeting (both require verbal comprehension, both require a problem state).
3. One task is highly automated and doesn't require a problem state.
Tasks that have been practiced to the point of automaticity don't consume central bottleneck resources or the problem state resource. Driving on a familiar highway is automatic enough that you can carry on a conversation. Typing is automatic enough that you can focus on the content you're composing rather than the keystrokes.
But notice: for knowledge workers, the "tasks" that matter — writing, reading code, debugging, designing, reviewing — are virtually never automatic. They are inherently novel, requiring active problem state maintenance and central executive engagement. The things you can automate alongside them are relatively trivial.
4. Context-switching cost is low because the problem state is simple or externally stored.
If you can fully offload the problem state of Task A to an external representation (a document, a checklist, a clear stopping point) such that re-entry is cheap, then alternating between A and B becomes more viable. The cost of switching is dominated by problem-state reload time. If there's no complex mental model to reconstruct, the cost is low.
This is why alternating between two procedural tasks with clear checkpoints (e.g., process this form, then process that form) is much cheaper than alternating between two creative or analytical tasks (e.g., write this section of the spec, then debug this architectural issue).
The Conditions Where Mono-Tasking Dominates
Single-task focus is unambiguously superior when:
- The task requires deep problem-state maintenance: Any work where you need to hold a complex mental model — writing a design doc, debugging a multi-component system, conducting a code review that requires understanding architectural intent, synthesizing research into a coherent argument.
- Both potential tasks are cognitively demanding and share resource pools: Two verbal-cognitive tasks, two tasks requiring visual attention and working memory. The research is unequivocal that performance on both degrades.
- Quality matters more than throughput: Dual-tasking doesn't just slow you down; it increases error rates. For tasks where errors are expensive (writing contracts, reviewing security-sensitive code, making strategic decisions), the quality cost of divided attention exceeds any throughput gain.
- The task benefits from sustained attention and flow: Csikszentmihalyi's flow state and Newport's deep work framework are consistent with the cognitive science here. The central bottleneck and problem state resource work most efficiently when focused on a single demanding task. Interruptions, even brief ones, force problem-state reloading that can take minutes for complex cognitive work (Mark, 2005, found 23+ minutes for full re-engagement after significant interruptions; Carnegie Mellon research found even brief interruptions increased task completion time by up to 23%).
Why Multi-Tasking (>2) Is Almost Always Wrong for Knowledge Work
The research case against juggling three or more cognitively demanding tasks simultaneously is strong:
- Triple-task costs persist even after extensive dual-task training (Stefani et al., 2025). The skills that help you manage two tasks don't cleanly transfer to three.
- Metacognitive monitoring degrades (Konishi et al., 2021). You lose the ability to accurately assess your own performance, which means you can't effectively self-correct or prioritize.
- Task coordination itself becomes a resource-consuming activity. With two tasks, coordination is relatively simple (alternate). With three or more, the scheduling problem becomes its own cognitive burden, consuming resources that could be devoted to the actual work.
- Error rates compound non-linearly. Each additional task doesn't just add its own error probability — it degrades the executive control that would catch errors in the other tasks.
For knowledge work — coding, design, writing, analysis — where tasks almost universally require problem state maintenance, verbal/spatial processing, and central executive engagement, multi-tasking beyond two is a net negative on both throughput and quality.
Practical Framework
Key References
- Pashler, H. (1994). Dual-task interference in simple tasks: Data and theory. Psychological Bulletin, 116(2), 220–244.
- Wickens, C. D. (2002). Multiple resources and performance prediction. Theoretical Issues in Ergonomics Science, 3(2), 159–177.
- Wickens, C. D. (2008). Multiple resources and mental workload. Human Factors, 50(3), 449–455.
- Salvucci, D. D., & Taatgen, N. A. (2008). Threaded cognition: An integrated theory of concurrent multitasking. Psychological Review, 115(1), 101–130.
- Borst, J. P., Taatgen, N. A., & van Rijn, H. (2010). The problem state: A cognitive bottleneck in multitasking. Journal of Experimental Psychology: Learning, Memory, and Cognition, 36(2), 363–382.
- Sigman, M., & Dehaene, S. (2006). Dynamics of the central bottleneck: Dual-task and task uncertainty. PLoS Biology, 4(7), e220.
- Held, M., Rieger, J. W., & Borst, J. P. (2024). Multitasking while driving: Central bottleneck or problem state interference? Human Factors, 66(5), 1564–1582.
- Stefani, M., Sauter, M., & Mack, W. (2025). Multi-tasking costs in triple-task performance despite dual-task preparation. Memory & Cognition, 53(6), 1637–1655.
- Konishi, M., Berberian, B., de Gardelle, V., & Sackur, J. (2021). Multitasking costs on metacognition in a triple-task paradigm. Psychonomic Bulletin & Review, 28(6), 2075–2084.
- Schumacher, E. H., et al. (2001). Virtually perfect time sharing in dual-task performance: Uncorking the central cognitive bottleneck. Psychological Science, 12(2), 101–108.
- Ruthruff, E., Van Selst, M., Johnston, J. C., & Remington, R. (2006). How does practice reduce dual-task interference: Integration, automatization, or just stage-shortening? Psychological Research, 70(2), 125–142.
- Dux, P. E., Tombu, M. N., Harrison, S., Rogers, B. P., Tong, F., & Marois, R. (2009). Training improves multitasking performance by increasing the speed of information processing in human prefrontal cortex. Neuron, 63(1), 127–138.
- Verghese, A., Garner, K. G., Mattingley, J. B., & Dux, P. E. (2016). Prefrontal cortex structure predicts training-induced improvements in multitasking performance. Journal of Neuroscience, 36(9), 2638–2645.
- Maquestiaux, F., Lague-Beauvais, M., Ruthruff, E., & Bherer, L. (2008). Bypassing the central bottleneck after single-task practice in the psychological refractory period paradigm. Memory & Cognition, 36(7), 1262–1282.
- Maquestiaux, F., Lague-Beauvais, M., Ruthruff, E., Hartley, A., & Bherer, L. (2010). Learning to bypass the central bottleneck: Declining automaticity with advancing age. Psychology and Aging, 25(1), 177–192.
- Maquestiaux, F., Didierjean, A., Ruthruff, E., Chauvel, G., & Hartley, A. (2013). Lost ability to automatize task performance in old age. Psychonomic Bulletin & Review, 20(6), 1206–1212.
- Maquestiaux, F., Ruthruff, E., Defer, A., & Ibrahime, S. (2018). Dual-task automatization: The key role of sensory-motor modality compatibility. Attention, Perception, & Psychophysics, 80, 752–772.
- Strobach, T., & Schubert, T. (2024). A mechanism underlying improved dual-task performance after practice: Reviewing evidence for the memory hypothesis. Psychonomic Bulletin & Review, 31, 1035–1053.
- Bender, A. D., Filmer, H. L., Garner, K., Dux, P. E., et al. (2017). Dynamic, continuous multitasking training leads to task-specific improvements but does not transfer across action selection tasks. npj Science of Learning, 2, 14.
- Anguera, J. A., Boccanfuso, J., Rintoul, J. L., et al. (2013). Video game training enhances cognitive control in older adults. Nature, 501(7465), 97–101.
- Strobach, T., & Schubert, T. (2017). No evidence for task automatization after dual-task training in younger and older adults. Psychology and Aging, 32(1), 28–41.
- Mark, G., Gonzalez, V. M., & Harris, J. (2005). No task left behind? Proceedings of CHI '05.
Newsletter
Get new posts in your inbox
Bring your team together to build better products. Fresh takes on remote collaboration and AI-driven development.